
Database Development
The database is the collection of an organized in a way that can be easily accessed, queried, retrieved and the database can be updated at any time.Steps involved in database development
- Data Collection/Availability Of Data
- Data Processing
- Organization & Management Of Data

Data Collection/Availability Of Data
Depends on the objective of the program to develop a database, data is then collected according to it, for example, gene sequences, gene expression data. Databases can also be developed for orphan genes and proteins having no translational activity described (not an orphan but have not been characterized experimentally). For these TrεMBL databases were created.Secondary databases were developed when working on a protein that needed to be analyzed in silicon. For this purpose, new databases were developed, for example, Prosite the data of patterns, motifs and domains were stored in such a way that significant match can be shown or functional activity can be detected through these databases i.e whether the proteins have features that have been described earlier or not.
An important aspect of data collection is to analyze the data source i.e from where data can be found. The data sources can be,
- Existing databases. (in case of developing secondary database)
- Available literature publications. (Initially, biological databases were developed through these, particularly data of motifs. Through analytical tools, results were analyzed & organized in a way that it could be used for identification of the particular motif in other proteins either well established or a new one).
- Survey forms/through specific questionnaires. (In case of disease data hospital factors genetic history, personal characteristics, etc. such information is also available in some publications as well).
Data Collection is the most lengthy phase-in database development.
Data Processing
The data is processed after collection. The first step in it is checking the duplicate records. The chances of duplicity or redundancy are more when there is more than one data source. Manual checking takes time. In excel, such records can be checked. One can design a utility for well-checking redundancy.Bioinformatics is regarded as a multidisciplinary field because the input is given from various fields. A team of individuals develops such a program i.e. specific development.
In database development, various things now fall on the principle of automation. Codes are available online to perform a function. Instead of writing whole programs, simple commands can be given. By changing parameters, own results can be obtained.
The duplicacy in numerical data can be checked through excel. if data is composite i.e. categoric data + numerical data then a program is added in excel. Duplicacy is checked on a single column. As each database has a specific id then it can be used to check duplicacy but if there are two or more databases then on different IDs records will be the same. In such a case, the description will be checked. Thus it has to be seen that by selecting which column duplicacy can be checked.
Organization & Management Of Data
Management can be done either through programs or through database management systems. The latter can interlink various queries and tables. Access & SQL are examples of database management systems. The goal is to organize data in a way that the objectives of the database can be achieved (search, query, retrieval).To bifurcate data and to keep it in patches is important so that its management & access becomes easy.
Different models are used for organizing data in databases.
In-excel, data cannot be interlinked it can be interlinked in Access. Data of different tables can be merged given as single output.
Models Of Databases
- Hierarchical Model
- Network Model
- Relational Model work
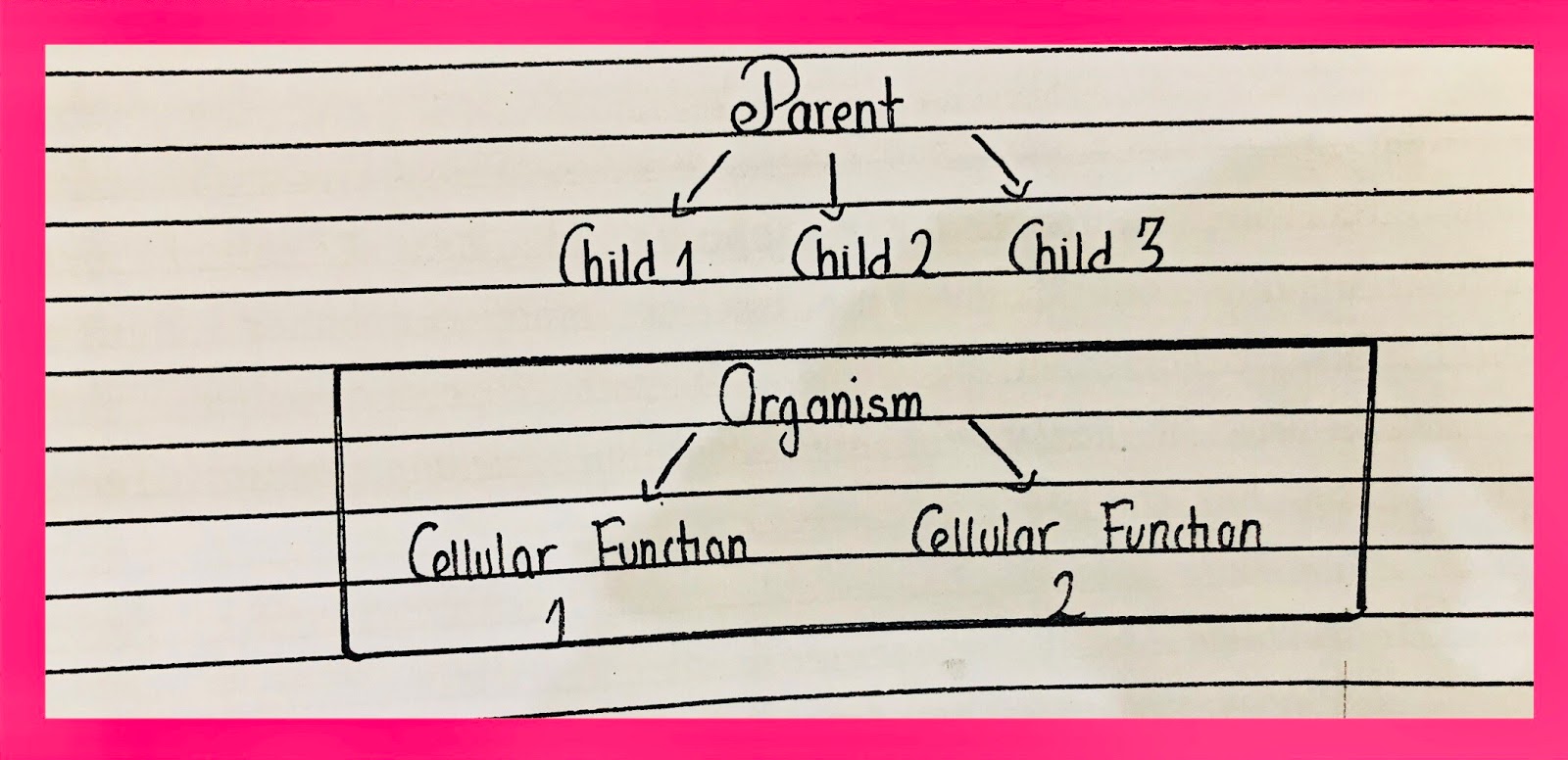
Hierarchical Model
- The data is managed or organized by maintaining a hierarchical.
- The phylogenetic tree is an example of a hierarchical model.
- No intermixing.
- The organization is like that of a parent & child.
Network Model
- Organization when according to function instead of the organism then it will be a network model.
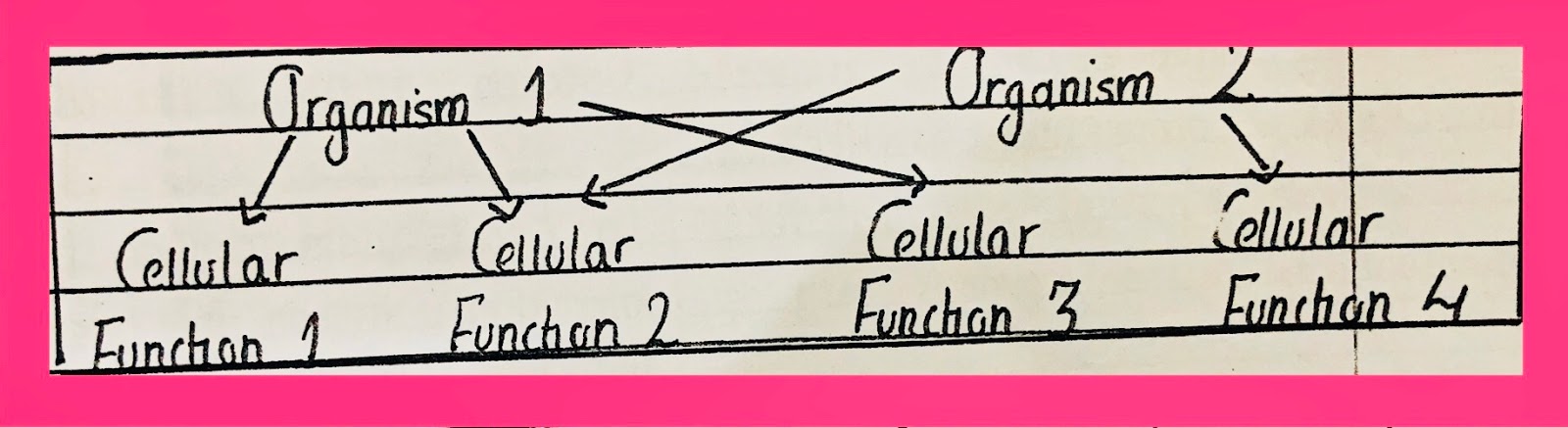
- Some data is interlinked. When the function is typed as a keyword then sequences of both organisms will come.
In the case of a hierarchical network, an organism has to be selected & then the function is studied. For example, ensemble. Data of other organisms is available as well but the search is organism-specific. In the case of selecting the "all organism" the network model will be followed.
In some cases, at one stage data is arranged in network model wise while at other stages it is in hierarchical model wise.
(Operators & Truncations are used in accordance with models).
In network, any function in an organism can be searched. restriction can be made as well (not to select some organism). If only one organism is selected the data will be in the hierarchy.
Relation Model
In biological databases, the relation model is mostly used. e.g in Uniprot, data follows the relation model.In databases, there are tables or directories.
[A pathway on which ultimately all files are present. If through the table, data cannot be managed then the directory is used.]
There will be a relation between all tables & directories. A common is used to develop relationships. through a common column, all entries can be linked with one another e.g clicking on a specie id, protein id can be opened. By creating a link between the two, a separate table can be generated. Merging tables will increase their size thus through links, reality can be established. The common column is called as Primary Key.
Data Mining is an inter database i.e. one database accesses other & brings data. It does not occur intra database. The relational database is intra database.
The relation can be turned on & off this flexibility is available like in Unipot some fields can be removed
Pieces of information come throughout various directories and are arranged.
Algebraic Operations can also be applied;
- Restrict; remove types (rows ) that don't satisfy some criteria.
- Project; remove column (fields)
- Product; merge tuple pairs from two relations in all possible ways.
- Join; merged tuple must satisfy some criteria for joining otherwise pair is removed.
Editor's Recommendation:
- Analysing Metabolic Pathways
- Protein Threading Sequence
- Ab Initio Protein Structure Prediction
- Homology Modeling
- Hot Start PCR, Multiplex PCR, Avoiding Contamination In PCR, Advantages, and Disadvantages in PCR
- DNA Damage
- Docking | Protein-Protein Docking | Protein-Ligand Docking
- Functional Regulation | Genetic Aspect | Indirect Aspects
- Functional Analysis At Structure Level
- PTMs and Functional Regulations
- Modeling Cellular Processes
- PCR Reagents | Stochastic Effect | STR Classification
- DNA Degradation
- DNA Quantification | Human DNA Quantification Method | Advantages
- Desirable Characteristics of STR used in Forensic DNA typing
- DNA Ladders
- Metabolic Pathways
- Non-Human DNA
- Mitochondrial DNA
- Integrated Genomic Circuits
- Real-Time PCR
- Shutter Product Formation
- STR Sites
- Mini STR Sites
- Molecular Diagnosis of Genetic Diseases
- Immuno Quantitative Assay
Database Development
 Reviewed by Abdullah
on
June 19, 2020
Rating:
Reviewed by Abdullah
on
June 19, 2020
Rating:
Reviewed by Abdullah
on
June 19, 2020
Rating:
No comments:
Don't add any Spam link in comment box.